
编程范式
左耳朵耗子在极客时间的编程范式游记,记录了自己熟悉的部分,不熟悉的javascrip,go语言没有记录。
编程语言发展到今天,出现了好多不同的代码编写方式,但不同的方式解决的都是同一个问题,那就是如何写出更为通用、更具可重用性的代码或模块。
那就是通过使用一种更为通用的方式,用另外的话说就是抽象和隔离,让复杂的“世界”变得简单一些。
类型
不管任何语言都有数据类型。数据类型是对内存的抽象,不同的类型,会有不同的内存布局和内存分配策略,也有不同的操作方式。
目前语言大致可以分为两类:一类是静态类型语言,如 C、C++、Java,一种是动态类型语言,如 Python、PHP、JavaScript 等。
所以,每个语言都需要一个类型检查系统。 静态类型检查是在编译器进行语义分析时进行的。 动态类型检查系统更多的是在运行时期做动态类型标记和相关检查。所以,动态类型的语言必然要给出一堆诸如:is_array(), is_int(), is_string() 或是 typeof() 这样的运行时类型检查函数。
泛型编程
为了更通用的编程,首先拿出来抽象的就是类型。屏蔽掉数据和操作数据的细节,让算法更为通用,让编程者更多地关注算法的结构,而不是在算法中处理不同的数据类型。
先从c语言开始。C 语言是一个静态弱类型语言,在使用变量时需要声明变量类型,但是类型间可以有隐式转换。
C语言的类型泛型基本上来说就是使用void *关键字或是使用宏定义。
void swap(void* x, void* y, size_t size)
{
char tmp[size];
memcpy(tmp, y, size);
memcpy(y, x, size);
memcpy(x, tmp, size);
}
#define swap(x, y, size) {\
char temp[size]; \
memcpy(temp, &y, size); \
memcpy(&y, &x, size); \
memcpy(&x, temp, size); \
}
c语言缺少强大的泛型,很难设计出通用的算法。
理想情况下,算法应是和数据结构以及类型无关的,各种特殊的数据类型理应做好自己分内的工作,算法只关心一个标准的实现。
c++的泛型
c++应该是泛型实现最完整的。先来看看 C++ 是如何有效解决程序泛型问题的,我认为有三点。
第一,它通过类的方式来解决。
- 类里面会有构造函数、析构函数表示这个类的分配和释放。
- 还有它的拷贝构造函数,表示了对内存的复制。
- 还有重载操作符,像我们要去比较大于、等于、不等于。 这样可以让一个用户自定义的数据类型和内建的那些数据类型就很一致了。
第二,通过模板达到类型和算法的妥协。
- 模板有点像 DSL,模板的特化会根据使用者的类型在编译时期生成那个模板的代码。
- 模板可以通过一个虚拟类型来做类型绑定,这样不会导致类型转换时的问题。 模板很好地取代了 C 时代宏定义带来的问题。
第三,通过虚函数和运行时类型识别。
- 虚函数带来的多态在语义上可以支持“同一类”的类型泛型。
- 运行时类型识别技术可以做到在泛型时对具体类型的特殊处理。
这样一来,就可以写出基于抽象接口的泛型。拥有了这些 C++ 引入的技术,我们就可以做到 C 语言很难做到的泛型编程了。
对比c和c++实现的search。
c语言版本:
int search(void* a, size_t size, void* target,
size_t elem_size, int(*cmpFn)(void*, void*) )
{
for(int i=0; i<size; i++) {
if ( cmpFn (a + elem_size * i, target) == 0 ) {
return i;
}
}
return -1;
}
c++语言版本:
template<typename T, typename Iter>
Iter search(Iter pStart, Iter pEnd, T target)
{
for(Iter p = pStart; p != pEnd; p++) {
if ( *p == target )
return p;
}
return NULL;
}
c语言版本中我们必须传入size来表示被void*擦除类型后类型的大小,还必须传入cmpFn来定义数字和字符串不同的比较。而且c语言只能适应内存连续的顺序数组。
在c++中解决了上面的所有问题。用typename T抽象了数据类型,在模板特化中并不会丢掉数据类型,也就不需要传入数据类型的大小。并且重载了==操作符,不管是int还是字符串还是自定义类型,都能做比较。最后用了迭代器模式,支持所有的容器类型。
函数式编程
特点
- stateless:函数不维护任何状态。函数式编程的核心精神是 stateless,简而言之就是它不能存在状态,打个比方,你给我数据我处理完扔出来。里面的数据是不变的。
- immutable:输入数据是不能动的,动了输入数据就有危险,所以要返回新的数据集。
函数式语言有三套件,Map、Reduce 和 Filter。
修饰器模式
和AOP一样,扩展函数的功能,可以很容易地将一些非业务功能的、属于控制类型的代码给抽象出来(所谓的控制类型的代码就是像 for-loop,或是打日志,或是函数路由,或是求函数运行时间之类的非业务功能性的代码)。 如python里的修饰器
def hello(fn):
def wrapper():
print "hello, %s" % fn.__name__
fn()
print "goodbye, %s" % fn.__name__
return wrapper
@hello
def Hao():
print "i am Hao Chen"
Hao()
@hello的效果和Hao = hello(Hao)是一致的。
代码的执行结果如下:
$ python hello.py
hello, Hao
i am Hao Chen
goodbye, Hao
面向对象编程
一切都是对象,符合真实世界的抽象,在大型项目中广泛应用。有三大特性:封装、继承、多态。并且有很多优秀的设计模式。
依赖倒置
在设计整个软件架构的时候,我们需要模块化,需要不同的方式来解耦。依赖倒置就是解耦,梳理架构的一种方式。
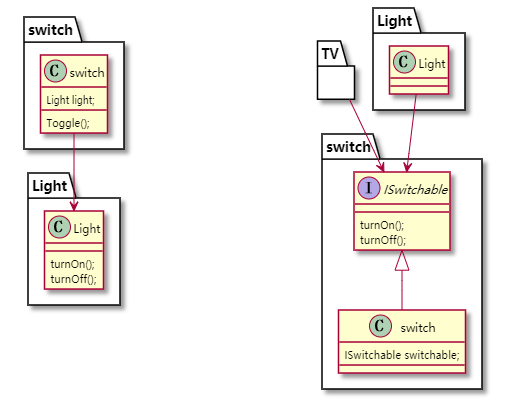
开始设计的时候,开关依赖灯,开关作为上层来调用Light。但是如果扩展到TV,空调等其它需要开关的东西,开光就不能复用。于是我们抽象出ISwitchable的接口,TV,空调来实现这个接口。在这里就实现了依赖倒置。现在switch成了一个底层、可以复用的类。
推荐资料
- 冒号课堂
- 《C++ 语言的设计和演化》