
鹿鸣的衣服
论文笔记 http://geometry.cs.ucl.ac.uk/projects/2019/garment_authoring/
鹿鸣的衣服动画采用的技术。阅读论文,做的笔记。
CG产业中衣服动画会消耗美术师大量的时间。因为随着人物角色的运动,衣服的动画会产生复杂的变形。在传统的CG制作中,可能用一些软件模拟物理环境,来形成衣服的动画,但是需要配置,调整大量的参数来支持模拟衣服的变形。这些参数包括服装的材质信息,simulator的参数,环境的参数等。
更常见的做法是用关键帧,再线性插值出其他帧,但是随着人物的运动,衣服会有复杂的变形,所有一般需要20%的关键帧,同样需要大量的劳动力。
米哈游尝试用deep learning来更好的插值出普通帧。将关键帧降低到只需要1-2%,从而大大减少CG的制作时间。整个框架大概分为下面三步。
1. shape discriptor
先用autoencoder训练服装mesh的latent表示。将4000多个顶点的服装降低到30 dimension(论文写的50,代码是30)。可以让germent shape在不同分辨率和type下保持一致。训练结束后,fix其权重,用作后面的整体训练。
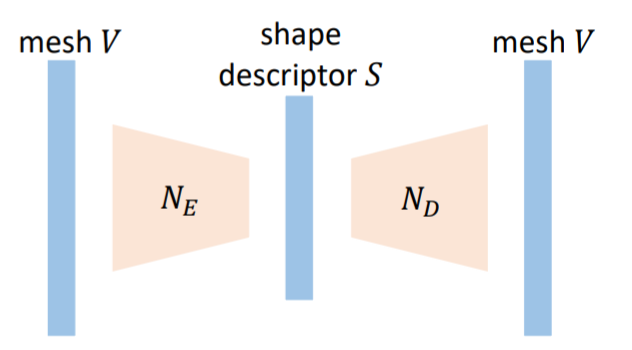
loss函数不仅衡量了输入和输出的顶点差异。而且衡量了输入的顶点之间的差和输出的顶点之间的差值,将mesh的关系也纳入了考虑。这样训练处的mesh的restruction error会更小。函数如下:
Loss function:
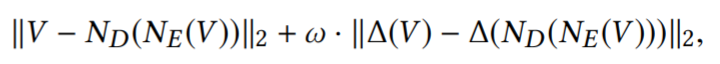
∆(·) is the Laplacian operator。为相邻顶点和顶点之间的差值组成的矩阵。实际运算中,我们通过mesh的顶点关系,生成M矩阵。M*V就可以得到 ∆(V)。
Normalization
input之前会normaliza,算loss的时候,会把数据还原。
不同encoder的比较:
 可以看到加入了Lalpacian的reconstruction error更小。
可以看到加入了Lalpacian的reconstruction error更小。
2. motion invariant encoding
根据关键帧的mesh和motion,Fe就能在latent space中的intrinsic parameter。然后应用Fd就能推导其它帧的服装形状。
网络架构:
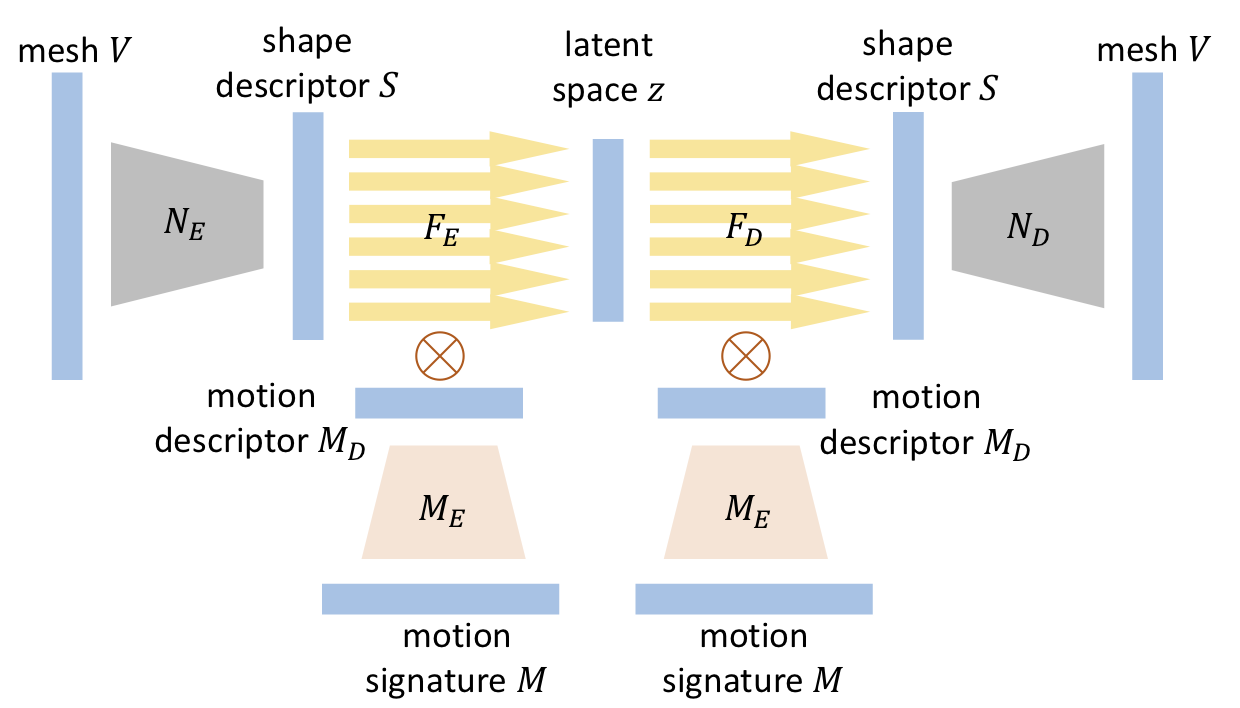
motion descriptor
Motion signature是过去100 frame,每帧24个关节的数据。motion signature的dim非常大,所以先用autoencoder降维度。 motion autoencoder的网络架构和shape descriptor差不多一样,但是是和整个网络一起训练的。所以没有自己的loss function。最后应用softplus activation,保证结果为非负数,以作为系数使用。
为什么一起训练。
Fe 和 Fd
inspired by phase-functioned neural network,这里要结合Md作为系数。Md为30dim,这里用30个subnetwork。每个network都是线性的。计算30次的前向传播后,用Md作为系数来blend30个subnetwork每层的结果。
Loss function
对同一批参数(θ)生成的动画来计算Loss。所以第一项代表同一参数,在latent空间应该对应同一个位置,第二项是解码前后的shape应该是一致的,作为正则避免所有动画都对应到latent空间的同一位置。
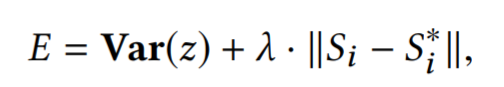
优化器
用的RMSProp优化器。
optimizer = optim.RMSprop(model.parameters(), lr=lrate, alpha=0.99, eps=1e-8, weight_decay=0., momentum=0.1, centered=False)
3. refinement
因为数据集的噪音和数字的精度问题,难免有穿模的情况。所以训练后,用refinemn步骤,解决穿模问题 。
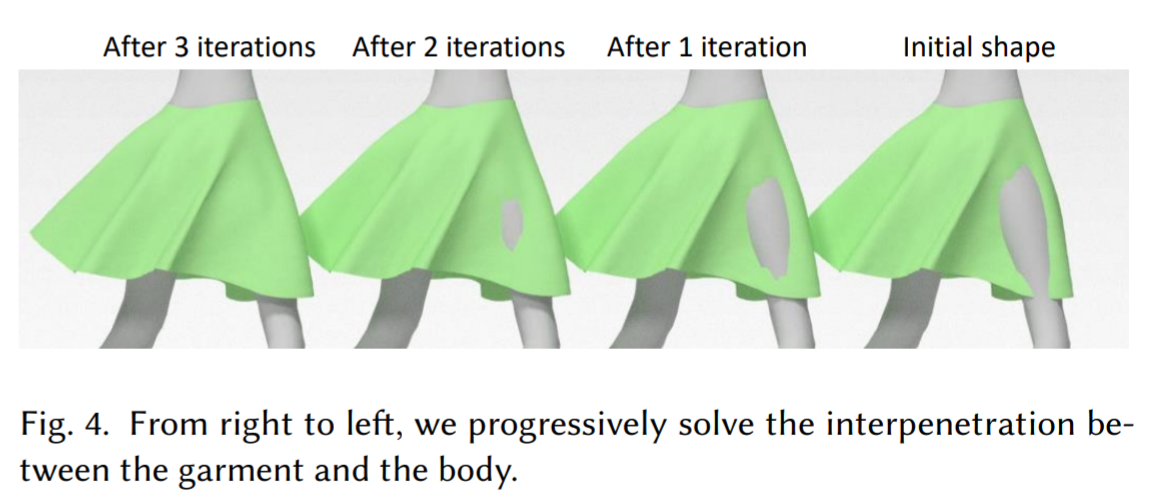
具体步骤如下:
- 找到所有在body内的衣服mesh顶点。
- 找到其对应的body surface的position。
- 最小化下面的函数。
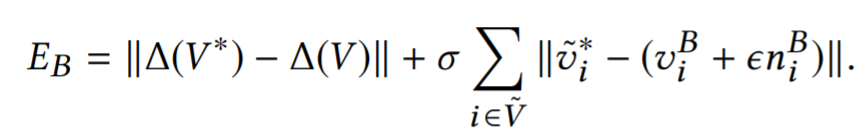
如果第一项和第二项都为0,就可以得到最小值。展开函数,发现未知量的方程数大于未知量数,所以可以利用最小二乘,拟合一个误差最小的解。