
深度学习介绍
深度学习有时候又叫深度神经网络,是机器学习下的分支,是一个具体的算法。自从2012年在图像识别算法中打败其它所有的算法后,成为机器学习中的一枝独秀。并且在2016年alphaGo打败围棋世界冠军后,变得家喻户晓。一时间人人都在畅想人工智能会给我们的生活带来怎样的变化,除了围棋,还能在那些方面超过我们 。
本文希望对能深度学习的原理做简单的解释,帮助我们理解深度学习到底是什么,究竟能改变些什么。
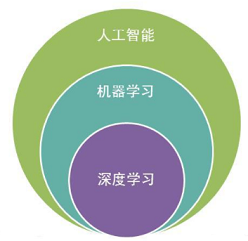
现状
深度学习目前已经在多个领域里得到了实际的应用,包括图像分类、语音识别、自然语言处理、搜索结果优化、广告定向投放等。并且还在不断尝试新的领域。这些技术已经被各行各业应用并实实在在的影响着我们的生活。比如支付宝的人脸识别,电视遥控器的语音遥控。
原理
直观的理解,深度学习就是要建立一种映射,就像我们中学所学的函数方程,将数据代入变量x就可以得到结果y。这个方程就是一种映射,而深度学习就是要通过已有的数据,提取出数据的特征x,标记好数据应该得到的结果y,然后把x和y的对应关系交给深度学习来不断的训练,最终找到一个合适的方程。这个方程不仅对现有数据代入特征x能到到预期的结果y,而且对以后未被标记的新数据,代入方程也能得到正确的结果y。这种需要标记数据的算法,也统称监督学习。
逻辑回归
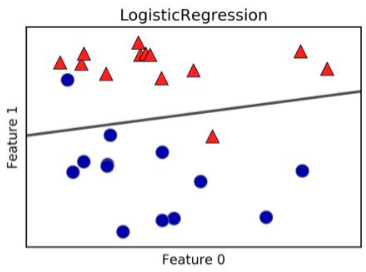
由简入难,先看一个二分类的问题。如图,图中的图形有三角形和圆形两类,并且图形的位置由Feature0和Feature1唯一确定。是否存在一个方程,代入(Feature0)和
(Feature1)的值我们就能得到次位置是三角形的概率。概率如果大于0.5就为三角形,小于0.5就为圆形。
如何寻找这样的方程呢?考虑如果存在这样一个方程:。代入
和
就能得到它是三角形的概率。
这个方程有、
和
三个参数的值需要确定,暂且都称其为权重。其大概流程如图所示。通过不断的更新权重,使预测值和真实值之间的差距最小。从而得到合适的权重值。
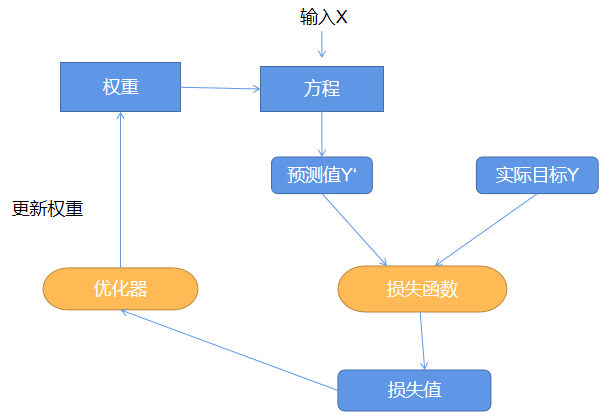
选择合适的损失函数和优化器是算法的核心。常见的就是交叉熵和梯度下降。
- 交叉熵(Cross Entropy):是使用最多的,度量Y和Y两个概率之间的差别。
- 梯度下降:优化器基本是梯度下降算法的变体。求出损失函数当前的梯度(斜率)dw,沿着梯度方向以速度a更新权重,就能使损失函数的值减小。(a就叫做学习率,是最常调节的参数)
在不断更新权重后,最后形成的函数,就能图中的黑线,能够区分出大部分的三角形和圆形。这个算法也叫做逻辑回归。
问题升级
形如直线或者单曲线的分类,在面对更复杂问题的时候表达力是不足。将逻辑回归串联成网络,就形成了强大的神经网络。而所谓的深度神经网络的“深度”,就是因为其中较多的hidden layer。
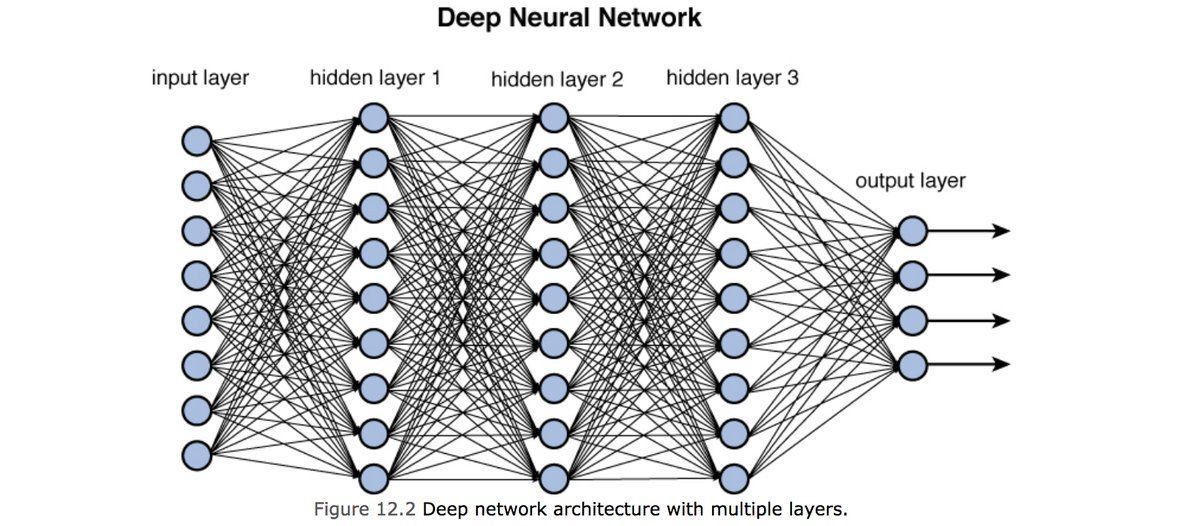
在形成网络后,会增加十分多的计算量。于是多了诸如前向传播,后向传播的算法,把很多计算并行化。将数据并成多维数组,也就是张量(Tensor),然后批量运算就可以大大减少运算时间。所有GPU因为强大的并行浮点数运算,能减少神经网络的运算时间。
优化
项目的第一步就是建模,选择合适的模型至关重要。循环神经网络(RNN)和卷积神经网络(CNN)是最常见的两个。调节合适的超参数,包括层数,每层多少单元,批处理数,学习率等;应用合适的优化算法和算法参数,以达到理想的训练效果。
正则化(Regularization)
正则化可以防止过拟合。强制模型的权重只能取较小的值,从而限制模型的复杂度。常用的两种。
- L2正则:修改cost函数,增加权重系数的平方。
- Dropout:最常用的正则化方法,在每次迭代中随机去掉一些节点。让训练不依赖于任何特定的输入变量。
deep learning里的例子在应用正则化后的效果:
| **model** | **train accuracy** | **test accuracy** | 3-layer NN without regularization | 95% | 91.5% |
| 3-layer NN with L2-regularization | 94% | 93% |
| 3-layer NN with dropout | 93% | 95% |
Adam
Adam(Adaptive Moment Estimation)是少有的对所有模型都有效的优化算法。结合了RMS prop算法和带动能的随机梯度下降算法。主要是对学习率进行更合理的变化。
实践
在面对实际问题的时候,一般为后获取数据,将数据集划分为训练集和测试集,然后不断建模,调参,训练。再不断的调整中,摸索出最佳算法和参数。
结论
深度学习是处在工程应用走在学术研究前面。有些算法并没有严格的论证,更多是根据工程试验的效果来调整模型和参数,以达到理想的效果。而深度学习也只是映射了特定数据和结果的对应关系,所以训练出来的结果并不能平迁到其它领域,更谈不上通用智能了。